

Aspect-based Document Similarity for Research Papers — Read a Paper
Aspect-based Document Similarity for Research Papers — Read a Paper
This paper talk about identifying similar research papers using aspect based similarity to improve granularity of RS like applications

Aspect-based Document Similarity for Research Papers
Traditional document similarity measures provide a coarse-grained distinction between similar and dissimilar documents…arxiv.org

The need for Aspect-based Similarity
Recommender systems help people find more relevant items. One of the use cases is to help researchers find relevant papers for their work. One way to improve such models would be to use user feedback to update the model. But in cases where user feedback is sparse or unavailable, content-based approaches and corresponding document similarity measures are used. Generally, Recommender system recommend a document depending on whether it is similar or dissimilar to the seed document. This similarity assessment neglects the many aspects that can make two documents similar. One can even argue that similarity is an ill-defined notion unless one can say to what aspects the similarity relates. For scientific papers, the similarity is often concerned with multiple facets of the presented research like methods, findings, etc. Using this, one can obtain specifically tailored recommendations.
Experiments
The section titles from citations are used as labels for document pairs. The sections define the aspects of similarity. A Transformer model with titles and abstracts as input is used for classification.
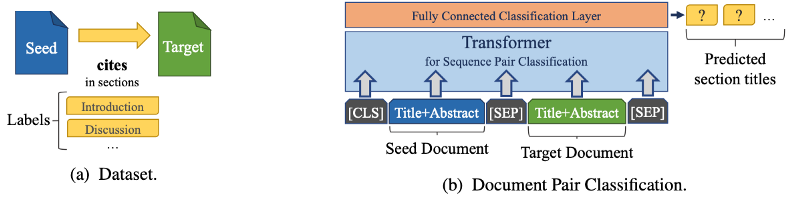
Datasets
Human annotated data for research paper recommendations is costly and usually limited to small quantities. To mitigate the data scarcity problem, researchers rely on citations as ground truth. When a citation exists between two papers, the two papers are considered to be similar. To make the similarity aspect-based, they transfer the idea to the problem of multi-label classification. As ground truth, the title of the section in which the citation from paper A (seed) to B (target) occurs as label class. The classification is multi-class because of multiple section titles and multi-label because paper A can cite B in multiple sections.
Datasets Adopted
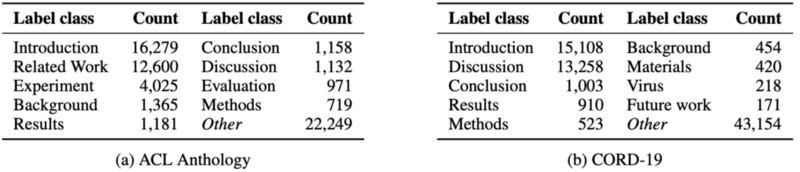
Data Preprocessing
The section titles are normalized (lowercase, letters-only, singular to plural) and combined sections are resolved into multiple ones (Conclusion and Future work to Conclusion; Future Work). DBLP and Semantic Scholar APIs are queried to match citations and retrieve missing information from the papers. Invalid and duplicate papers are removed. The datasets are divided into 10 classes according to their number of samples. The first nine compose the most popular section titles, and the tenth groups the remaining ones. The resulting class distribution is unbalanced but it reflects the true nature of the corpora.
Negative Sampling
In addition to the 10 positive classes, a new class named None was introduced that works as a negative counterpart for the positive samples in the same proportion. The None document pairs are randomly selected and are dissimilar. A random pair of papers is a negative sample when the papers do not exist as a positive pair, are not co-cited together, do not share any authors, and were not published in the same venue. These samples let the model distinguish between similar and dissimilar documents.
Systems
The paper focuses on sequence pair classification with models based on Transformer architecture. It investigates six Transformer variations and an additional baseline for comparison. The titles and abstracts of research papers are used as input to the model whereby [SEP] separates the seed and target paper.
As a baseline, a bidirectional LSTM was used. SpaCy tokenizer and word vectors from FastText was used. The word vectors were pretrained on the abstracts of the ACL Anthology or CORD-19 datasets.
The transformer architectures used were:
BERT
Covid-BERT
SciBERT
RoBERTa
XLNet
ELECTRA
Hyperparameters & Implementation
LSTM
10 epochs
batch size b = 8
learning rate = 1^(-5)
2 LSTM layers with 100 Hidden size, attention
dropout with probability d = 0.1
Vanilla PyTorch
Transformer based Techniques
4 training epochs
learning rate = 2^(-5)
batch size b = 8
Adam Optimizer
Evaluation was conducted in a stratified k-fold cross-validation with k = 4. The source code and datasets are publicly available here.
Results
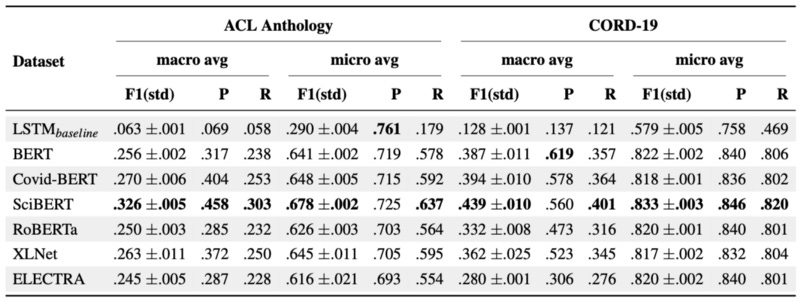
Given the overall scores, SciBERT is the best method. All Transformers outperform the LSTM baseline in all metrics except the micro-precision on ACL Anthology. The gap between macro and micro average results is due to discrepancies between label classes.
Label Class Evaluation
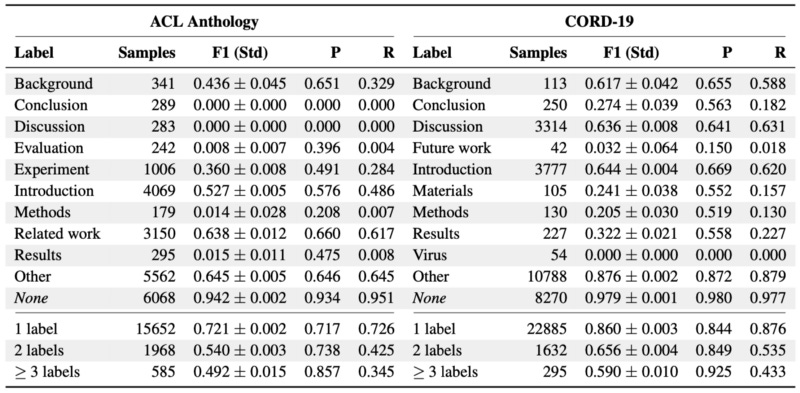
The None has the highest F1-score with a large margin. Other shows the second-best F1-score, which in a similar-dissimilar classification scenario can be interpreted as an opposite class to the None label. The remaining positive labels yield low scores, but also a lower number of samples. The lower number of samples does not necessarily correlate with low accuracy. The discrepancy in the number of samples and difficulty in uncovering latent information from aspects contribute to the decrease in some labels’ accuracy.
We also notice that F1 scores decrease on both datasets as the number of labels increases. This is due to decreasing recall. The precision increases with more labels.
Qualitative Evaluation
The predictions from SciBERT were qualitatively evaluated on ACL Anthology. For each example, SciBERT predicts whether the seed cites the target paper and in which section the citation should occur. The predictions are then manually examined for their correctness.
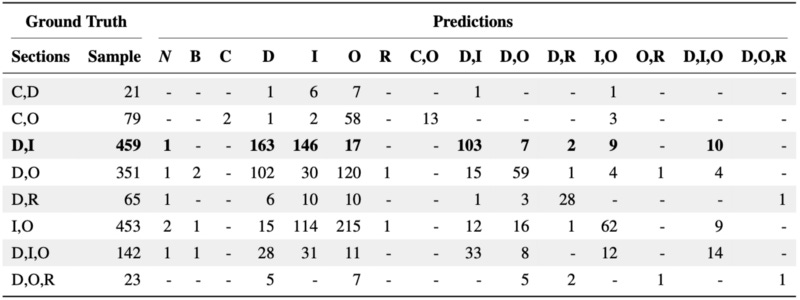
Qualitative evaluation does not contradict quantitative findings. SciBERT distinguishes documents at a higher level and classifies which aspects make them similar. The aspect-based predictions allow us to assess how two papers relate to each other at a semantic level.
SciBERT outperforms all other methods in the pairwise document classification. In the case of the experiments in the paper, transferring generic language to a specific domain decreased the performance. A possible explanation is the narrowly defined vocabulary in ACL Anthology and CORD-19 datasets. The main research objective of this paper was to explore methods that are capable to incorporate aspect information into traditional similar-dissimilar classification. In this regard, the results were deemed promising.