

Beyond Accuracy: Behavioral Testing of NLP models with CheckList — Read a Paper
Beyond Accuracy: Behavioral Testing of NLP models with CheckList — Read a Paper
This paper introduces CheckList — a task-agnostic methodology for testing NLP models.

Beyond Accuracy: Behavioral Testing of NLP models with CheckList
Although measuring held-out accuracy has been the primary approach to evaluate generalization, it often overestimates…arxiv.org

One of the primary goals of training NLP models is generalization. Testing in the wild is expensive and does not allow for fast iterations. So the standard paradigm for evaluating models is to use train-validation-test splits to estimate the accuracy of the model. The held-out datasets are often not comprehensive and contain the same biases as the training data. This might result in overestimating real-world performance. Also, aggregating performance into a single statistic makes it difficult to figure out where the model is failing and how to fix it.
Introducing CheckList
This paper proposes a new evaluation methodology and an accompanying tool CheckList, for comprehensive behavioral testing of NLP models. It guides users in what to test, by providing a list of linguistic capabilities which are applicable to most tasks. It also provides different test types to break down potential capability failures into specific behaviors. The implementation of CheckList includes multiple abstractions that help users generate a large number of test cases easily. Traditional benchmarks reveal that models are as accurate as humans. CheckList on the other hand reveals a variety of severe bugs where commercial and research models do not effectively handle basic linguistic phenomena.
CheckList
Users CheckList a model by filling out cells in a matrix, each cell potentially containing multiple tests.
Capabilities
CheckList encourages users to consider how different natural language capabilities are manifested in the task at hand and to create tests and evaluate models on each of these capabilities. The authors suggest that users consider at least the following capabilities:
Vocabulary + POS (Parts of Speech tagging)
Taxonomy
Robustness
NER (Named Entity Recognition)
Fairness
Temporal
Negation
Coreference Semantic Role Labelling
Logic
Test Types
The users are prompted to evaluate each capability with three different test types (when possible):
Minimum Functionality tests (MFT) — Inspired by unit tests in software engineering, it is a collection of simple examples to check a behavior within a capability. Useful for detecting when models use shortcuts to handle complex inputs without mastering the capability.
Invariance (INV) — Inspired by software metamorphic tests, an invariance test is when we apply label preserving perturbations to inputs and expect the model to remain the same. Different perturbation functions are needed for different capabilities. For example, changing the names for NER capability of Sentiment or introducing typos for Robustness capability.
Directional Expectation tests (DIR) — Also inspired by software metamorphic tests, it is similar to Invariance except that the label is expected to change in a certain way.
INVs and DIRs allow testing on unlabelled data as they test behaviors that don’t rely on ground truth labels, but rather on relationships between predictions after perturbations are applied.
Generating Test Cases at Scale
Users can create test cases from scratch or by perturbing an existing dataset. Writing from scratch requires significant creativity and effort, often leading to tests that have low coverage, or are expensive and time-consuming to produce. But it makes it easier to create a small number of high-quality test cases for a specific phenomenon that might be underrepresented or overlooked in the original dataset. Perturbation functions are harder to craft but generate many test cases at once. CheckList provides a variety of abstractions that scale-up test creation from scratch and make perturbations easier to craft.
Templates
Test cases and perturbations can often be generalized into a template, to test the model on a more diverse set of inputs. For example, “I didn’t live the food” can be generalized with the template “I {NEGATION} {POS_VERB} the {THING}”, where {NEGATION} = {didn’t, can’t say I, …}, {POS_VERB} = {love, like, …}, {THING=food, car, flight, service…} and generate all test cases with a Cartesian product.
Expanding Templates
Users are provided with an abstraction where a part of a template is masked and a masked language models (like RoBERTa) is used to suggest fill-ins. These suggested fill-ins can be filtered by the user to suit their needs. This can also be used in perturbations, like replacing neutral words for other words in the context. The users are also provided with some additional common fill-ins for general-purpose categories like Named Entities and protected group adjectives.
Open-source
An implementation of CheckList is available at https://github.com/marcotcr/checklist. Apart from the above mentioned features it also contains various visualizations, abstractions for writing test expectations and perturbations, saving/sharing tests and test suites such that tests can be reused with different models and by different teams, and general-purpose perturbations such as char swaps (to simulate typos), contractions, name and location changes, etc.
Testing SOTA models with CheckList
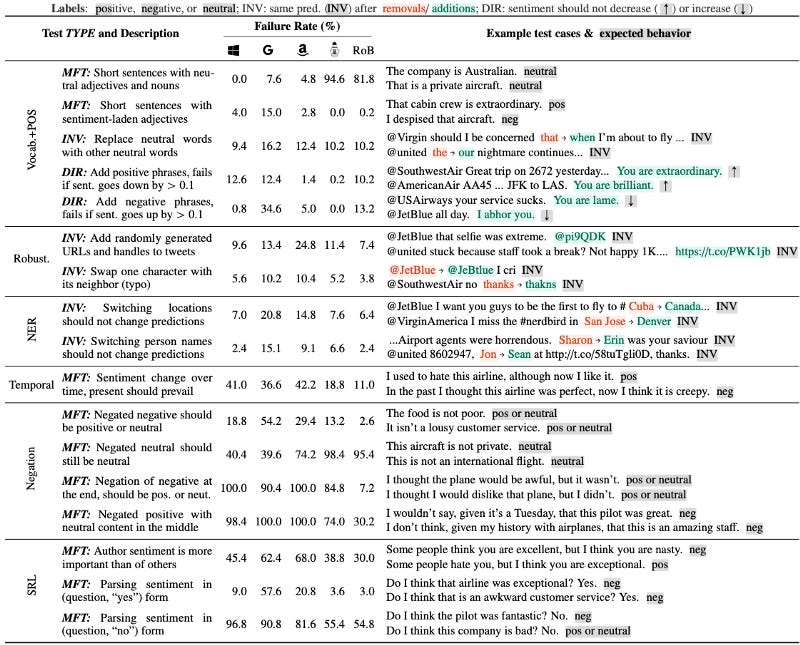
The paper CheckListed the following commercial Sentiment analysis models via their paid APIs:
Microsoft’s Text Analytics
Google Cloud’s Natural Language
Amazon’s Comprehend
The paper also CheckLists BERT-base and RoBERTa-base fine-tuned on SST-2 and the QQP database. For Machine Comprehension, a pre-trained BERT-large fine-tuned on SQuAD was used.
Results of the CheckList are shown in the following tables.


User Evaluation
CheckList leads to insights both for users who already test their models carefully and for users with little or no experience in a task. Some User Studies can be found in the paper demonstrating the ease of use and benefits of using CheckList.
Accuracy on benchmarks, although useful, is not always sufficient for evaluating NLP models. CheckList tests individual capabilities of the model by adopting principles from behavioral testing in software engineering. Since many tests can be applied across tasks as is or with minor variations, it is expected that collaborative test creation will result in the evaluation of NLP models that are much more robust and detailed, beyond just accuracy on held-out data. CheckList is open source, and available at https://github.com/marcotcr/checklist.