

Feature Stores — What, Why, Where and How?
Feature Stores — What, Why, Where and How?
The term feature store has been going around a lot these days. This post tries to shed some light and clarity on the topic.


But before we go into Feature Stores,
What are Features?
Features are independent properties that act as an input for your model. Consider the model
y = f(x)
Here x is your input vector, y is your output vector and f is your model. Each column in x are the features for your model. The machine learning model learn from the feature and updates its parameters during training to be able to make good predictions for the output.
Now,
What are Feature Stores?
I was introduced to Feature Stores when I attended apply(). Simply put, a Feature Store is a datastore that stores features. Sounds straight forward right? So why not just create an SQL or BigTable Database and get it over with? What makes feature stores so special? Well, the implementation is what makes it special. So let us see why we need feature stores to understand that.
Why Feature Stores?
To understand why we need feature stores, we need to know what the different phases of the Machine Learning Lifecycle are. They are listed below.
Planning — Understand the problem and the business objectives, determine the target variable and potential features, consider any possible limitations and define your success metrics.
Data — Aquire, explore and clean your data
Modelling — Build your model (Select, train and evaluate your model)
Production — Deploy your model and monitor it to identify any immediate or future issues
Now that we know the Machine Learning Lifecycle, we understand that we need features at two phases — Modelling and Production
When we are modelling, we will need features to train our model. I production, we might not get all the features from the prediction requests. So we might have to fetch the missing features.
Even though both these phases might need the same data, their requirements slightly differ. Modelling will use large amounts of data. So the data store must be optimized to handle this. In production, we will need data at really low latency to decrease the response times of our services.
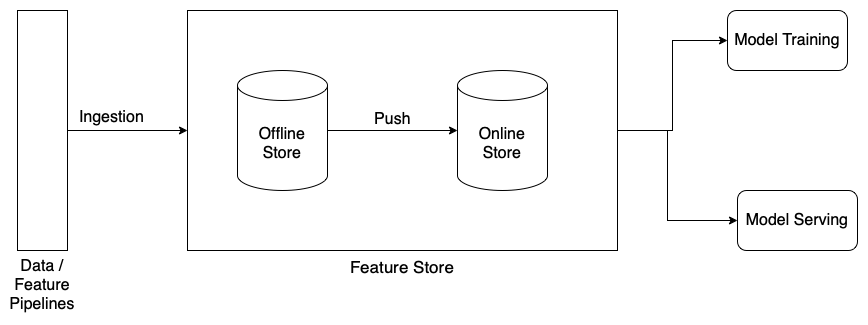
Features stores have two components — an Offline store and an Online Store.
The offline stores are generally high performance data stores like BigTable and Delta Tables. This is used by the training jobs to fetch large amounts of data to train the model.
The online stores are low latency data stores like Redis, AmazonRDS, sqlite, etc. This is used by the prediction services to get the features they need and make predictions.
Redis is an in memory database. AmazonRDS is a cloud datastore. Google Cloud Datastore can also be used.
Feature stores, using their APIs, add a level of abstraction so the Data Scientists and Machine Learning Engineers can have access to the same data and also have their requirements satisfied.
Where do you use a Feature Store?
Generally, the Feature pipelines generate the features the model needs and pushes the data into the offline store. The model trains the model using this data. Once the model is successfully trained and ready for deployment, the data in the offline store is pushed into the online store so the new model can start accessing it once deployed.
How do I start using a Feature Store?
There are a lot of Feature Stores available. MLOps Community has a great comparison of different available features stores. You can find it here. I have personally experimented with Feast and the Databricks Feature store and they are pretty good and have enough features to get the job done and some more.
More info on Feature Stores can be found here.